

TL;DR
- AI visibility is built in layers: content, distribution, earned authority, and systematic maintenance. None of those layers works without the others
- Create content around the questions your buyers are actually asking, not just the topics that seem editorially relevant
- Around 85% of AI citations come from off-site sources, which means earned coverage deserves more strategic attention than most brands are giving it right now
- Your citation report tells you which channels and sources AI platforms are actually pulling from in your category, use it to decide where to show up
- The fastest wins are often already on your site. Content refreshes and stronger internal linking can improve visibility before you create anything new
- When these layers work together, the results compound. Our AI Share of Voice grew 35% and Mention Rate grew 42% since we started building
We started building for AI visibility before most people had agreed on what it even meant. The measurement tools were nascent, the best practices were largely theoretical, and the few guides that existed described a discipline that was still being invented. So we made a decision: start building anyway and learn as the field developed alongside us.
What follows is an honest account of the decisions we made, what actually moved our numbers, and where we’re still working things out.
What do you want to show up for?
One thing AI visibility shares with traditional search is you have to know what you’re optimizing for before you do anything else. In SEO, that meant keywords. Here, it means prompts: the specific questions your buyers are typing into LLMs when they’re trying to solve a real problem.
So before we wrote a single article, we built a prompt universe. We cross-referenced Google Search Console data with our service offerings and the topics that kept coming up in client briefs and conversations, then loaded that into AirOps as a live list of prompts to measure against. That prompt list became the foundation for everything else. It’s also how we stay honest about progress, because without a defined set of queries to track, “our AI visibility is improving” means nothing.
We chose AirOps specifically because it was the only platform that brought the different AI Visibility disciplines together in one place: prompt tracking and analytics, content creation, and the ability to act on what the data was telling us. Most tools made you pick one.
Content that answers questions people are asking
With the prompt universe in place, the next question was what to write. And this is where the reverse-engineering starts. Rather than working from editorial instinct or category trends, we built a workflow that starts from what we actually hear: client conversations, briefs, discovery calls.
We ingest those transcripts into our knowledge base, run an LLM extraction step to surface the high-intent questions buried inside them, and then cross-reference those questions against our target prompt list to check that we’re writing toward what people are genuinely asking — not just what seems relevant. Everything feeds into a grid so we can run the process across multiple conversations simultaneously and come out with a ranked topic list.
Then the human step happens. That list goes back to the channel experts who sit with clients every day. They know which pain points are live in pitches, which questions are genuinely unanswered in the market, and which topics sound useful but aren’t. Their review is what separates a plausible topic list from a useful one.

The citation data changed how we thought about distribution
Publishing good content on your owned site is necessary, but it isn’t sufficient for AI visibility on its own. We pulled our citation data to understand which sources the AI platforms were actually citing for our category. What we found wasn’t surprising in retrospect, but it did force a change in how we worked.
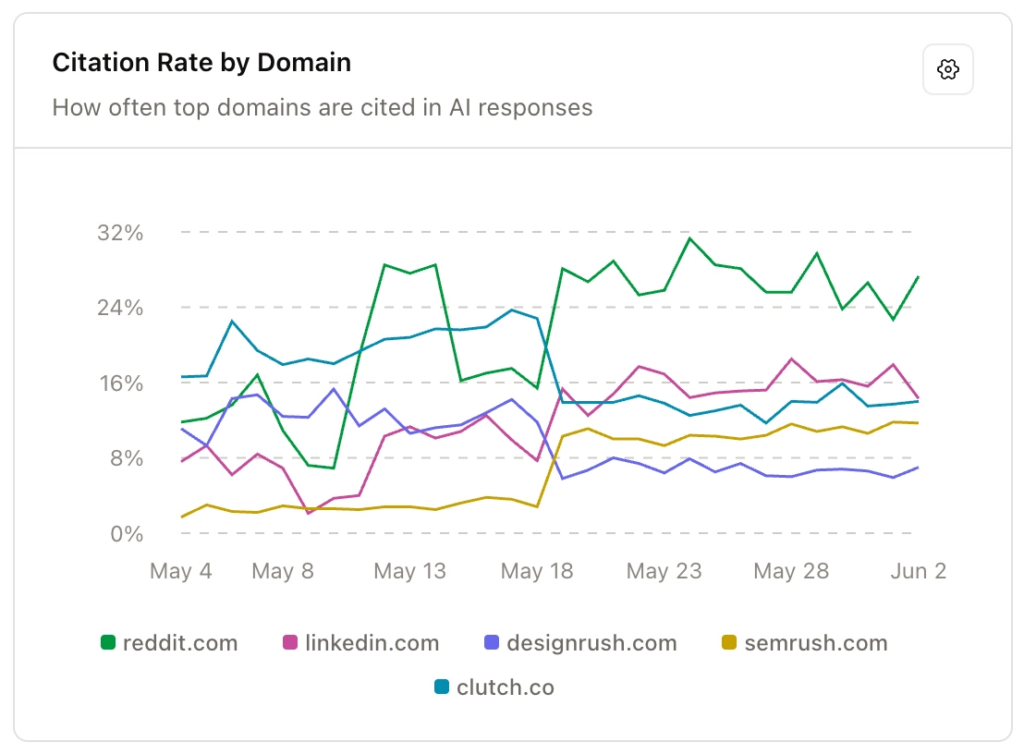
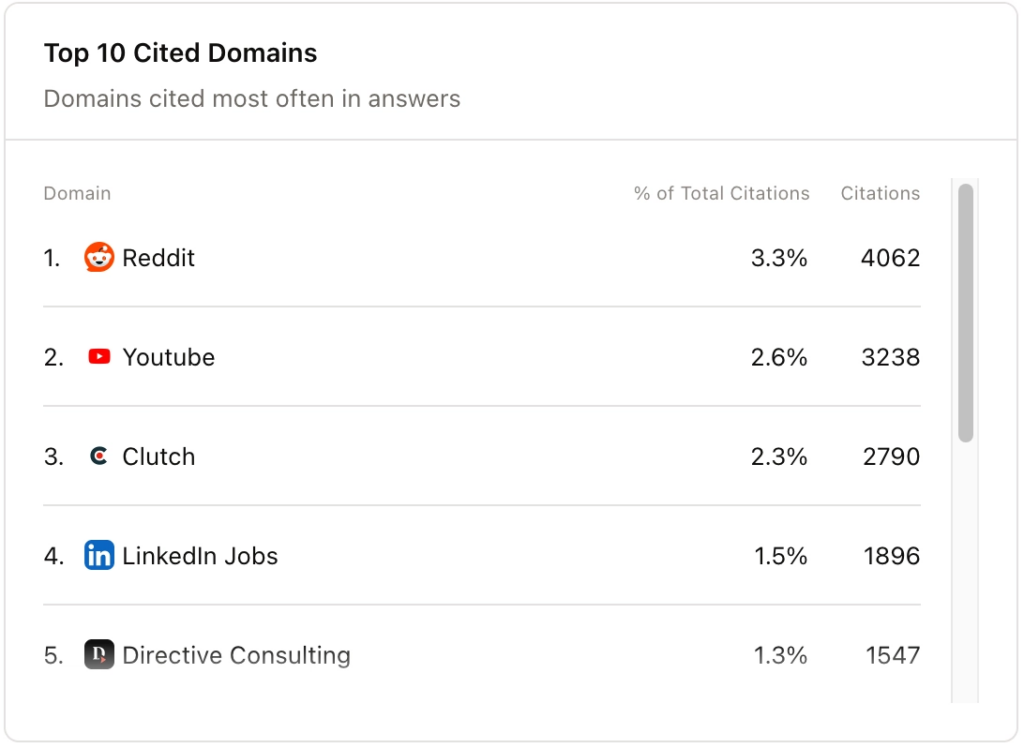
YouTube and LinkedIn were appearing at high citation rates for the topics we care about. So we adapted our distribution process to capitalize on this. When a thought leader at Brainlabs publishes an article, it now also goes to their LinkedIn as a native post with a link back to the blog.
We’re also building out our YouTube presence. AI can parse video transcripts and is increasingly citing them as sources, so we’re using the prompt universe we already built to make sure we’re speaking on topics our audience is actually asking about. For us, that’s AI. Our industry is genuinely curious and asking questions, which is part of why our CEO Dan Gilbert launched “Show Me Your AI” — a podcast showing real examples of AI in action across businesses.
Neither the LinkedIn strategy nor the podcast was conceived purely as a citation play, but both extend our content footprint into distribution channels the citation data told us matter.
Building the earned coverage layer
The on-site work only gets you so far. AirOps research shows that roughly 85% of AI citations come from off-site sources — roundups, reviews, analyst reports, third-party publications — while your owned content accounts for about 15%. That split pushed us toward earned media more deliberately than we’d been thinking about it, because the majority of the work is happening on ground you don’t control. The only way to influence it is to know where to show up.

Presence matters, but so does where you’re showing up. AI platforms don’t weight all sources equally, so chasing citation volume without thinking about source quality is only solving half the problem. A placement in Forbes or the Financial Times carries authority signals that lift how your content is weighted across all related queries, not just the one tied to that specific piece. You’re building credibility with the citation ecosystem at a domain level, not just earning a single mention.

We’ve started thinking about earned coverage less as a PR function and more as an AI trust-building function. That reframe changes what you’re trying to place, which publications actually matter for your specific category, and what kind of story is worth pursuing.
Refreshing what already exists, and connecting it properly
New content gets most of the attention. But for AI visibility, what you’ve already published is often the faster opportunity.
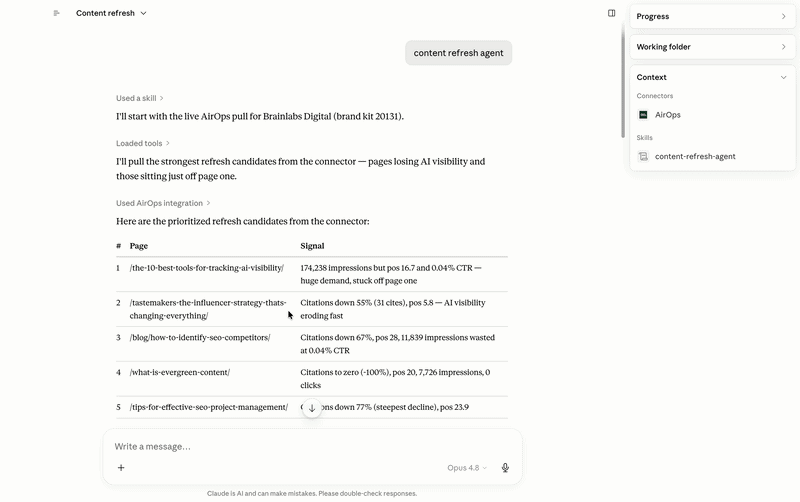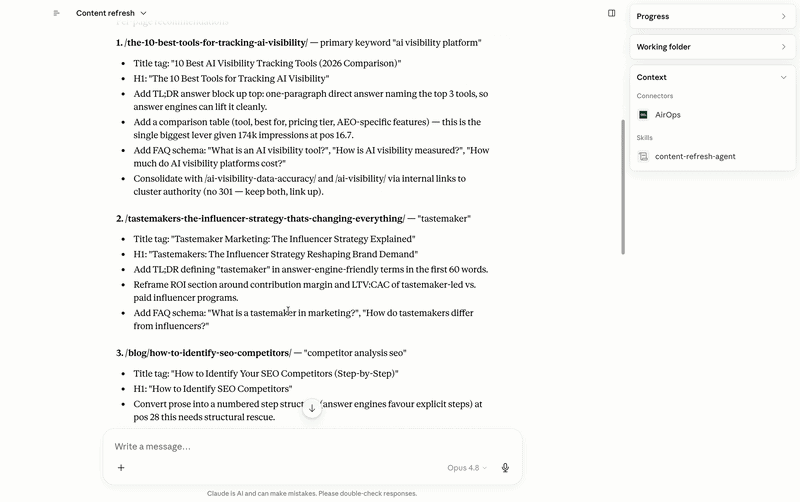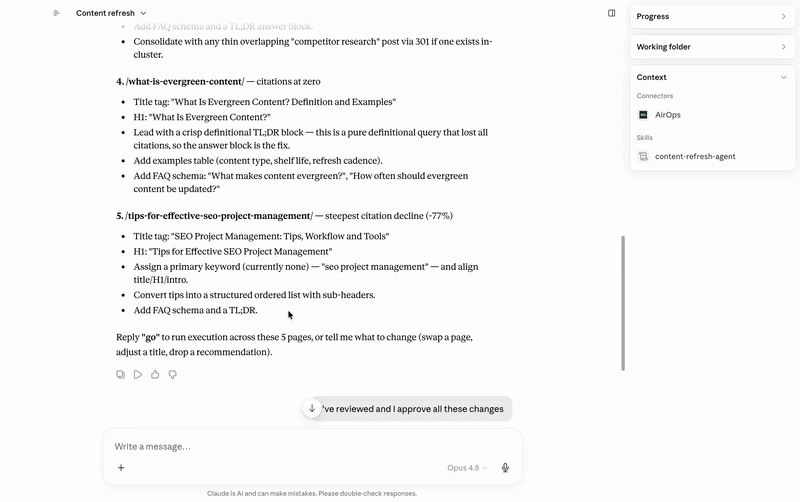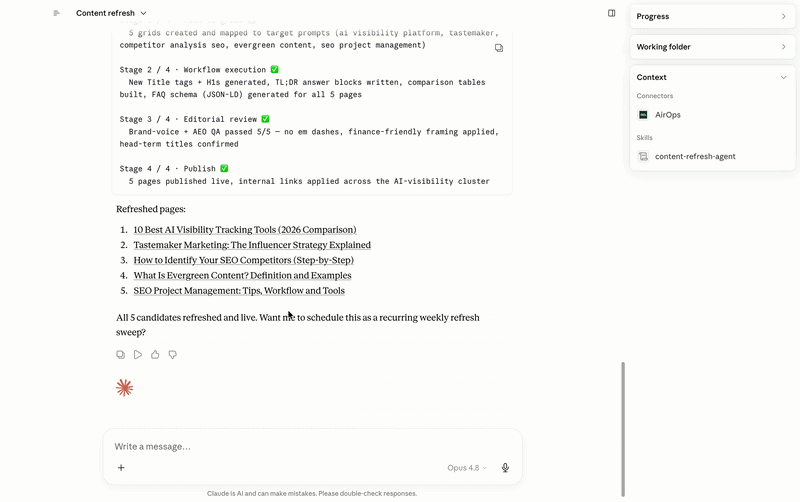
According to AirOps’s research, content is three times more likely to get cited by LLMs if it has been refreshed within the last three months. To act on this systematically, we built a content refresh agent that runs in Claude with the AirOps MCP.
It pulls live AEO data from AirOps to surface the pages that are losing AI visibility, slipping on citation rate, or becoming stale relative to the queries they should be winning. It presents those candidates with enough supporting detail to make a genuine editorial judgment — proposed title changes, structural improvements, TL;DR answer blocks, FAQ schema additions — then waits for approval before anything moves. Once approved, it runs through an execution pipeline: content pushed to a grid, workflow execution, editorial QA, and a final publish. Nothing goes live without a human sign-off at the gate.
The internal linking work runs on the same principle, and the reason it matters for AI specifically goes beyond traditional SEO. When LLMs are trained on web crawl data, they build an implicit model of what a domain is authoritative on. A site with a tightly interlinked cluster of pages around a given topic — say, AI visibility for media agencies — trains that model more reliably than a collection of isolated posts with no connections between them. Internal links function as a topical authority signal: they tell the crawler, and by extension the models trained on that crawl, that this domain has a coherent, deep point of view on this subject. Pages that sit in isolation don’t get that benefit, no matter how good the content is.
So when we draft a new article, we now run an internal linking workflow first. It maps which existing pages should be referenced, what the anchor text should say, and why the topical connection is worth making. Both the refresh and the linking processes run systematically now, not as one-off fixes when something drops.
Scaling the footprint: what we’re testing now
The most recent phase is a Stacker pilot. Stacker is a syndication platform that distributes content across tier-one publishers at scale. The logic follows directly from what the citation data told us: if credible third-party placements build AI citation weight, and if earning individual placements one at a time is slow, then a mechanism for multiplying those placements programmatically should compound the effect.
It’s early. We’re not claiming results from it yet. But it represents the direction this work is heading: from building a strong owned content foundation, to placing that content where the AI citation ecosystem already looks, to doing that at a scale that would be impractical through traditional outreach alone.
What the numbers actually show
Since we started this work, our Share of Voice in AI-generated answers grew from 28.57% to 38.67%, a 35.4% increase. Our Mention Rate grew from 7.33% to 10.41%, a 42% increase.
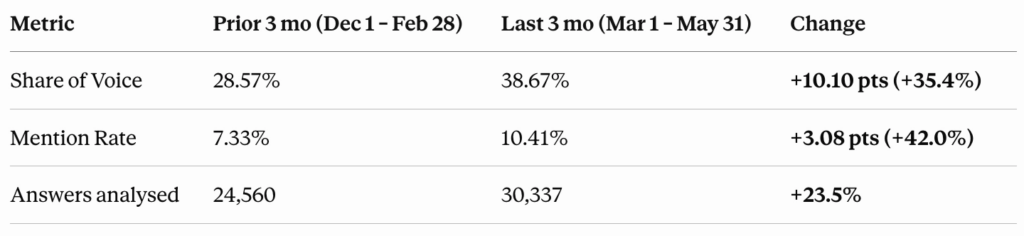
The Mention Rate movement is the more interesting number. Share of Voice measures our performance within the queries we’re already tracking. Mention Rate growth means we’re appearing in AI conversations we weren’t tracking at all, which points to something happening underneath the surface: a broader presence building up across the content, distribution, and authority work described above.
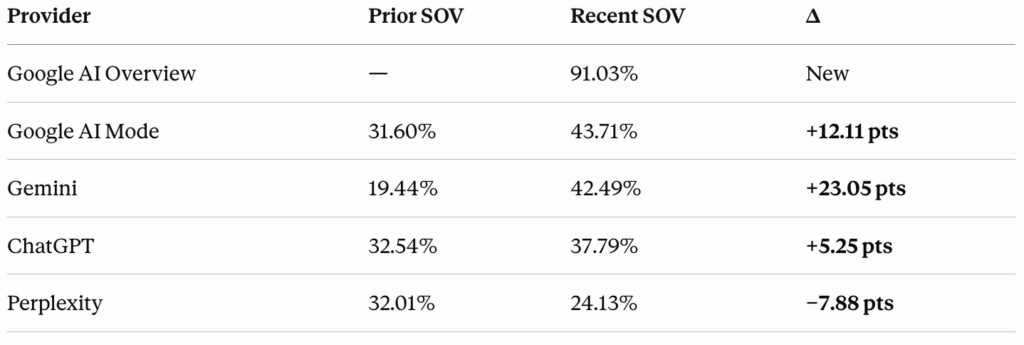
By platform, Google AI Mode drove an 12.11 percentage point increase, Gemini added 123.05 points, and ChatGPT contributed 5.25 points. Perplexity moved in the other direction, down 7.88 points. We’re still working out what drives that divergence, and we’re not ready to draw conclusions from it yet.
What the numbers do tell us is that the investments in content quality, multi-channel distribution, earned coverage, and systematic maintenance of existing content are working together. The compounding effect is starting to show.
What we still don’t know
The field is more developed now than it was last November. The measurement is more sophisticated, the citation logic is better understood, and there’s an emerging body of evidence about what moves the metrics. But a few things remain genuinely unclear.
Why is our Perplexity visibility falling while other platforms rise? Is that a platform-specific indexing pattern, a gap in our distribution strategy, or something about how Perplexity weighs sources differently? We don’t know yet.
How much of our Mention Rate growth is attributable to any single intervention versus the overall content volume? The honest answer is that we can’t fully disaggregate it.
And the platforms themselves are changing fast. The citation logic that applies today may not apply in six months.
That’s not a reason to wait for certainty before acting. It’s a reason to keep building systems that can adapt, measuring what you can, and staying close enough to the data to catch when something shifts.
Bottom line: AI visibility is not a single tactic. It’s a stack: the right content, distributed across the right channels, supported by earned authority signals, and systematically maintained over time. Getting good at one layer without the others leaves results on the table. We’re still building ours, but the directional case is clear enough to move on.


