

ScreamingFrog Beginner’s Guide
If you are new to search engine optimization (SEO) or coming across your first time using Screaming Frog, this post is for you!
A common issue I noticed as an intern was the significant amount of trouble interns had setting up and navigating the tools we use for SEO. While trying to find a balance between learning new concepts in SEO as a part-time intern and familiarizing ourselves with the tools we use daily, we noticeably had less time engaging with concepts.
My first crawl as an intern was for a site with over hundreds of thousands of URLs and I ran into a handful of problems I had to learn from. As you begin working in SEO, you will come across powerful tools that will aid you in finding valuable data. It is important to be able to utilize and navigate these tools as efficiently as possible.
A tool we often use is called Screaming Frog, a website crawler that crawls URLs and returns valuable data for us to analyze in order to audit technical and onsite SEO.
In this blog, we will be covering how to set up your device for Screaming Frog and configurations to be made in order to crawl a site, and executing your crawl. All of this will be beneficial in setting you up for success in using Brainlabs’ very own technical audit checklist and will ensure you’re getting the data you need to run your first audit.
Setting up your device
As you begin crawling sites, you will find some sites are larger than others and require more of your system’s memory to store and process the data that Screaming Frog finds. Before you start crawling websites, it would be beneficial to allocate more of your system’s RAM to Screaming Frog – allowing for more speed and flexibility for all future crawling. This will be necessary for sites with over 150k URLs to crawl.
Configuration > System > Memory
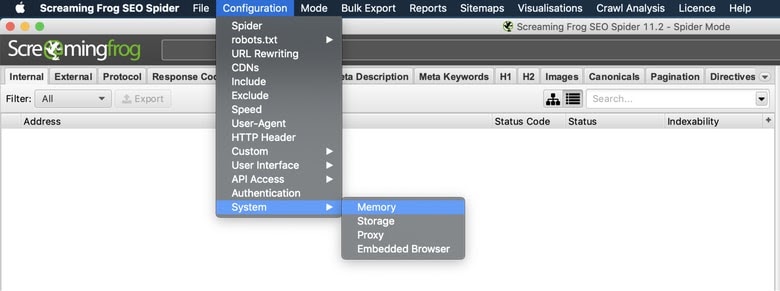
The default setting for 32-bit machines is 1GB of RAM and 2GB of RAM for 64-bit machines. I recommend using 8GB, which allows Screaming Frog to crawl up to 5 million URLs. Screaming Frog recommends using 2GB less than your total RAM, but be wary if you dedicate your total RAM your system may experience a crash.
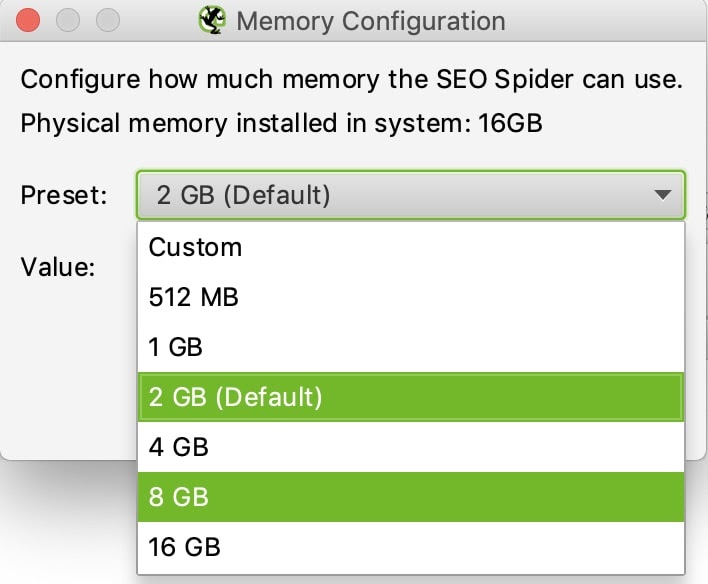
When you’re done allocating more RAM to Screaming Frog, you will need to restart your software for the changes to apply.
Configurations
Once you begin crawling sites, it’s important to adjust your configurations accordingly to make sure Screaming Frog is crawling efficiently as possible. Here I will show you some basic configurations I like to use.
Configuration > Spider > Basic
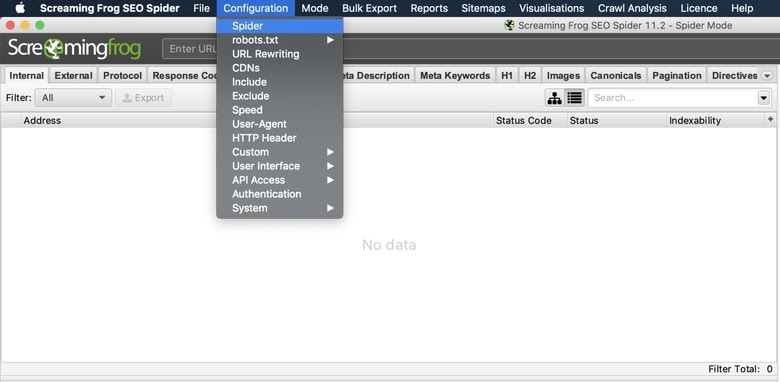
These are the default settings Screaming Frog has for every crawl. It is a good habit to set your configurations specific to the crawl you’re about to execute and make adjustments here.
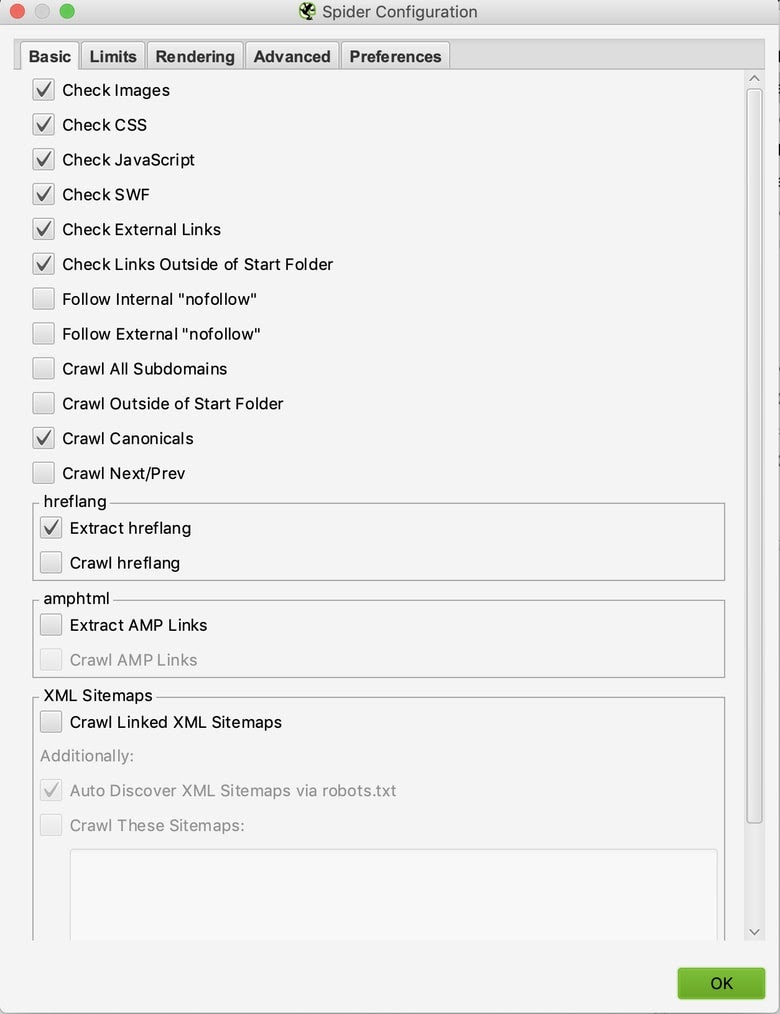
Here are the basic settings I use to run my tech audits:
- Follow Internal “nofollow”: Allows us to crawl internal links with “nofollow attributes” to check if our site is implementing this tag to show content we do/don’t want discovered or indexed.
- Crawl Canonicals: Allows us to crawl canonical link elements to check if we’re indicating what pages we want ranking.
- Crawl Next/Prev: Allows us to crawl rel=”next” and rel=”prev” elements to give us an idea if our site is clearly communicating the relationship between pages.
- Extract hreflang: Displays hreflang language, region codes, and the URL to check we are communicating the different variations of our site.
- Crawl Linked XML Sitemaps: Allows us to discover URLs in XML sitemaps.
- Auto Discover XML Sitemaps via robots.txt: Allows us to find sitemaps discoverable through robots.txt
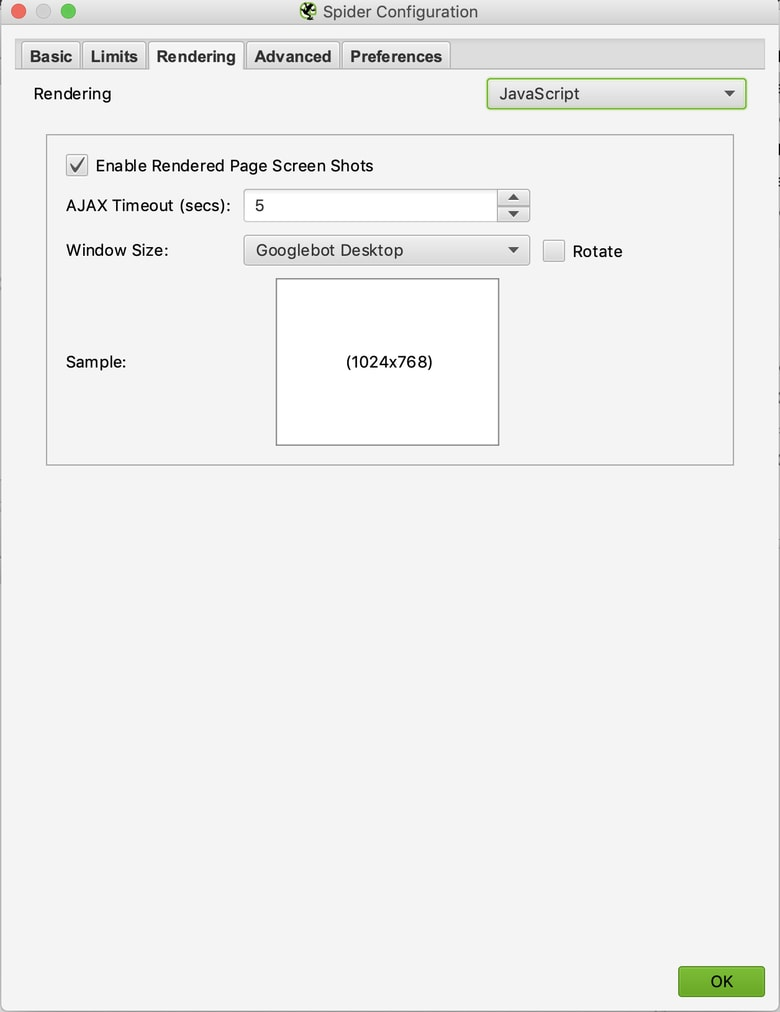
If you are dealing with a site that utilizes JavaScript and want to spot check internal navigation, you’ll need to execute a separate crawl with different configurations for that specific page, not the whole domain. Navigate to the “rendering” tab to make sure our crawler can find those instances. If you want to learn more about debugging javascript check out our Senior Consultant, Sergey Stefoglo’s Moz blog.
Configuration > Spider > Basic > Rendering
After spider configurations, we always need to set custom filters for specific things we want to show up in our crawl.
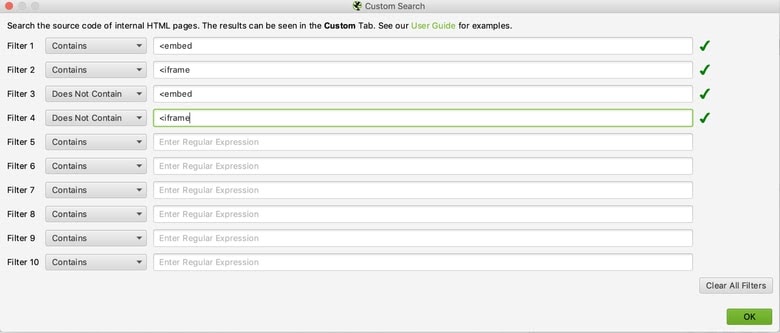
Configuration > Custom > Search
I regularly use these filters to include and exclude things I want to keep an eye out for and to make sure all pages are accounted for:
- <embed: Checks for any crucial content loaded in flash
- <iframe: Checks for any content loaded in iframe
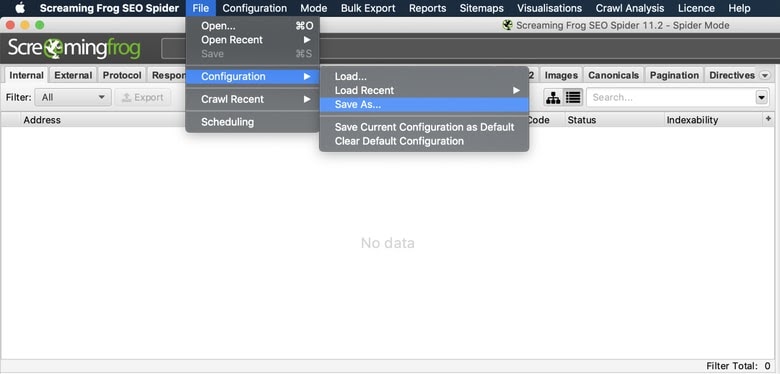
Now that you’ve got your configurations set for your initial crawl, you can save these configurations for future crawls so you don’t have to go through this process every time! Just load the configurations you need before running each crawl.
File > Configuration > Save As…
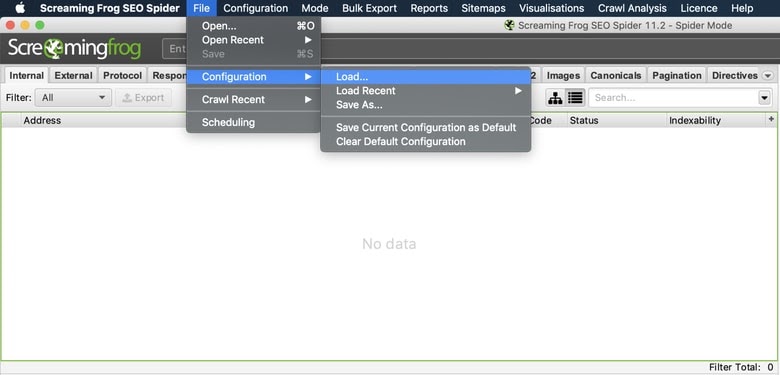
File > Configuration > Load…
Crawling Your First Site
Now that we’ve set up our system and made our configurations, the only thing left to do is to start crawling our site!
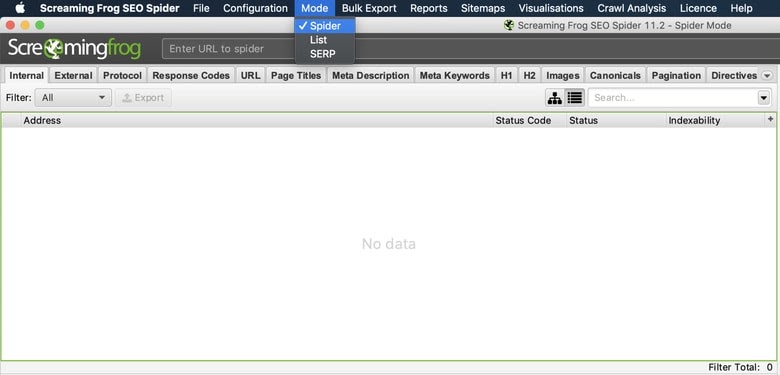
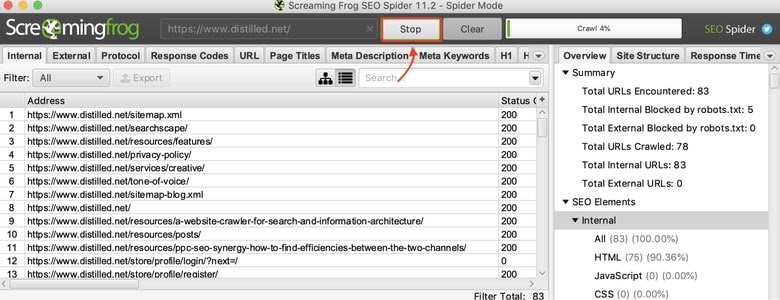
To crawl a website you will want to use Screaming Frogs default “Spider” mode. This will allow us to crawl the site and gather links based on our configurations and filters we created. For our example, we’ll crawl https://www.distilled.net/.
Mode > Spider > Enter URL > Click Start

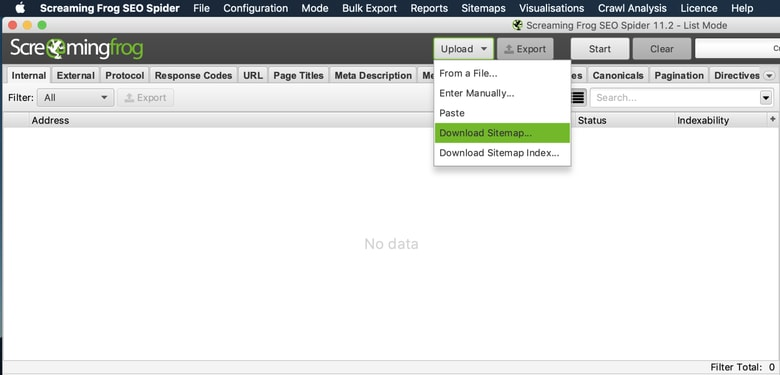
In addition to Spider mode, I also utilize “List” mode which will crawl a list of URLs that can come from a file or a simple copy and paste. For this example, we’ll use distilled.net’s sitemap URL.
Mode > List > Upload > Download Sitemap
Important things to consider when crawling:
- You can stop and resume your crawl as needed.
- Turning off your system or exiting Screaming Frog will result in losing your data.
- You can always save your crawl and resume to finish at a later time.
After crawling our site, it’s time to use the data we’ve collected and give it some context. If you haven’t already, I highly recommend reading the article, “Technical Audit Checklist for Human Beings” by Ben Estes, our Global VP of Product Design, SEO.
This article will help you transition into conducting your first technical audit using the tech audit checklist provided in Ben’s article. After reading this article and using our tech audit checklist, I hope you find insightful data that triggers your curiosity about the field of SEO.


