

Open-source website crawler for SEO
We’re all about effective and accountable search marketing. Part of being effective is being able to gather the data we need to diagnose an issue. For a while, we’ve been using a custom crawler to solve technical problems with our clients. Today, we’re making that crawler available to you.
This crawler solves three long-standing pain points for our team:
- Unhelpful stock reports. Other crawlers limit us to predefined reports. Sometimes these reports don’t answer our questions. This crawler exports to BigQuery, which lets us stay flex.
- Limited crawl scope. When crawling on your own computer, your crawl is limited by how much RAM you’ve got. Our crawler is so efficient that you’re more likely to run out of time than memory.
- Inflexible schema. Other crawlers generally export flattened data into a table. This can make it hard to analyze many-to-many relationships, like hreflang tags. This crawler outputs complete, non-flattened information for each page. With this data, the queries our team runs are limited only by their imaginations.
Our team still uses both local and hosted crawlers every day. We break out this custom crawler when we have a specific question about a large site. If that’s the case, this has proven to be the best solution.
To use the crawler, you’ll need to be familiar with running your computer from the command line. You’ll also need to be comfortable with BigQuery. This blog post will cover only high-level information. The rest is up to you!
Please note: This is not an official Brainlabs product. We are unable to provide support. The software is open-source and governed by an MIT-style license. You may use it for commercial purposes without attribution.
What it is
We’ve imaginatively named the tool crawl. crawl is an efficient and concurrent command-line tool for crawling and understanding websites. It outputs data in a newline-delimited JSON format suitable for use with BigQuery.
By waiting until after the crawl to analyze data, analysis can be more cost-effective. If you don’t try to analyze the data at all as you’re collecting it, crawling is much more efficient. crawl keeps track of the least information necessary to complete the crawl. In practice, a crawl of a 10,000-page site might use ~30 MB RAM. Crawling 1,000,000 pages might use less than a gigabyte.
Cloud computing promises that you can pay for the computing power you need, when you need it. BigQuery is a magical example of this in action. For many crawl-related tasks, it is almost free. Anyone can upload data and analyze it in seconds.
The structure of that data is essential. With most crawlers that allow data exports, the result is tabular. You get, for instance, one row per page in a CSV. This structure isn’t great for many-to-many relationships of cross-linking within a website. crawl outputs a single row per page, and that row contains nested data about every link, hreflang tag, header field, and more. Here are some example fields to help you visualize this:
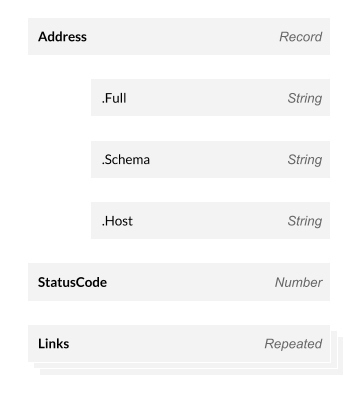
Some fields, like Address, have nested data. Address.Full is the full URL of the page. Other fields, like StatusCode, are simply numbers or strings. Finally, there are repeated fields, like Links. These fields can have any number of data points. Links records all links that appear on a page being crawled.
So using BigQuery for analysis solves the flexibility problem, and helps solve the resource problem too.
Install with Go
Currently, you must build crawl using Go. This will require Go version >1.10. If you’re not familiar with Go, it’ll be best to lean on someone you know who is willing to help you.
go get -u github.com/benjaminestes/crawl/...
In a well-configured Go installation, this will fetch and build the tool. The binary will be put in your $GOBIN directory. Adding $GOBIN to your $PATH will allow you to call crawl without specifying its location.
Valid commands
|
USAGE: crawl <command> [-flags] [args] |
|
| help | Print this message. |
| list |
Crawl a list of URLs provided on stdin. Example: |
| schema |
Print a BigQuery-compatible JSON schema to stdout. Example: |
| sitemap |
Recursively requests a sitemap or sitemap index from a URL provided as argument. Example: |
| spider |
Crawl from the URLs specific in the configuration file. Example: |
Configuring your crawl
The repository includes an example config.json file. This lists the available options with reasonable default values.
{
"From": [
"https://www.example.com/"
],
"Include": [
"^(https?://)?www\\.example\\.com/.*"
],
"Exclude": [],
"MaxDepth": 3,
"WaitTime": "100ms",
"Connections": 20,
"UserAgent": "Crawler/1.0",
"RobotsUserAgent": "Crawler",
"RespectNofollow": true,
"Header": [
{"K": "X-ample", "V":"alue"}
]
}
Here’s the essential information for these fields:
- From. An array of fully-qualified URLs from which you want to start crawling. If you are crawling from the home page of a site, this list will have one item in it. Unlike other crawlers you may have used, this choice does not affect the scope of the crawl.
- Include. An array of regular expressions that a URL must match in order to be crawled. If there is no valid Include expression, all discovered URLs could be within scope. Note that meta-characters must be double-escaped. Only meaningful in spider mode.
- Exclude. An array of regular expressions that filter the URLs to be crawled. Meta-characters must be double-escaped. Only meaningful in spider mode.
- MaxDepth. Only URLs fewer links than MaxDepth from the From list will be crawled.
- WaitTime. Pause time between spawning requests. Approximates crawl rate. For instance, to crawl about 5 URLs per second, set this to “200ms”. It uses Go’s time parsing rules.
- Connections. The maximum number of current connections. If the configured value is < 1, it will be set to 1 upon starting the crawl.
- UserAgent: The user-agent to send with HTTP requests.
- RobotsUserAgent. The user-agent to test robots.txt rules against.
- RespectNofollow. If this is true, links with a rel=”nofollow” attribute will not be included in the crawl.
- Header. An array of objects with properties “K” and “V”, signifying key/value pairs to be added to all requests.
The MaxDepth, Include, and Exclude options only apply to spider mode.
How the scope of a crawl is determined
Given your specified Include and Exclude lists, defined above, here is how the crawler decides whether a URL is in scope:
- If the URL matches a rule in the Exclude list, it will not be crawled.
- If the URL matches a rule in the Include list, it will be crawled.
- If the URL matches neither the Exclude nor Include list, then if the Include list is empty, it will be crawled, but if the Include list is not empty, it will not be crawled.
Note that only one of these cases will apply (as in Go’s switch statement, by way of analogy).
Finally, no URLs will be in scope if they are further than MaxDepth links from the From set of URLs.
Use with BigQuery
Run crawl schema >schema.json to get a BigQuery-compatible schema definition file. The file is automatically generated (via go generate) from the structure of the result object generated by the crawler, so it should always be up-to-date.
If you find an incompatibility between the output schema file and the data produced from a crawl, please flag as a bug on GitHub.
In general, you’ll save crawl data to a local file and then upload to BigQuery. That involves two commands:
$ crawl spider config.json >output.txt $ bq load --source_format=NEWLINE_DELIMITED_JSON dataset.table output.txt schema.json
Crawl files can be large, and it is convenient to upload them directly to Google Cloud Storage without storing them locally. This can be done by piping the output of crawl to gsutil:
$ crawl spider config.json | gsutil cp - gs://my-bucket/crawl-data.txt $ bq load --source_format=NEWLINE_DELIMITED_JSON dataset.table gs://my-bucket/crawl-data.txt schema.json
Analyzing your data
Once you’ve got your data into BigQuery, you can take any approach to analysis you want. You can see how to do interactive analysis in the example notebook.
In particular, take a look at how the nested and repeated data fields are used. With them, it’s possible to generate reports on internal linking, canonicalization, and hreflang reciprocation.
Bugs, errors, contributions
All reports, requests, and contributions are welcome. Please handle them through the GitHub repository. Thank you!
Please note: this is not an official Brainlabs product. We are unable to provide support. The software is open-source and governed by an MIT-style license. You can use it for commercial purposes without attribution.


